

Nel Post precedente sulla convergenza del BGP, ho posto l'accento su come sia possibile chiudere una sessione BGP senza aspettare la scadenza dell'Holdtime negoziato tra i due BGP peer.
In questo Post, e in Post successivi, poiché l'argomento è complesso, focalizzarò invece l'attenzione su cosa accade quando il BGP Next-Hop diventa irraggiungibile.
DAL BGP TIME-DRIVEN AL BGP EVENT-DRIVEN
Per capire la genesi del problema e il perché questo può allungare considerevolmente i tempi di convergenza, vediamo cosa accadeva nelle prime implementazioni del BGP nei router Cisco.
Per ciascun prefisso BGP tipicamente la risoluzione del BGP Next-Hop è di tipo ricorsivo. Con ciò si intende che spesso (non sempre comunque), il BGP Next-Hop non è direttamente connesso e quindi il router deve eseguire un nuovo lookup sulla Tabella di Routing (RIB) per trovare un percorso verso il BGP Next-Hop. Percorso determinato da un protocollo IGP (es. OSPF, IS-IS, ecc.), o anche, ma solo in situazioni particolarmente elementari, via routing statico.
Questa interazione tra BGP e protocolli IGP veniva implementata nei router (Cisco) dal un particolare processo noto come BGP scanner. Il processo BGP scanner esegue una scansione periodica della Tabella BGP attraverso la quale, vengono effettuati su tutti gli annunci presenti, vari controlli e aggiornamenti, come ad esempio, la raggiungibilità del BGP Next-Hop (in caso negativo l’annuncio viene eliminato dalla Tabella BGP, e se best-path, rifatto il processo di selezione per determinare il nuovo best-path), aggiornamenti della penalità del meccanismo Route Flap Damping, controllo degli annunci condizionati, ecc. . Il valore di default del periodo del processo di scanning è di 60 sec, valore che può essere variato attraverso il comando:
router(config)# router bgp <numero-AS>
router(config-router)# bgp scan-time <valore-in-secondi>
dove l’intervallo dei valori ammessi è [5, 60] . È bene tener presente che, un valore basso comporta vantaggi in termini di velocità di convergenza, ma per contro un maggiore impegno della CPU. Il valore effettivo del periodo del processo di scanning utilizzato dal router, può essere verificato attraverso il classico comando di visualizzazione “show bgp (ipv4 | ipv6) unicast summary” (nuova versione del vecchio e caro comando IPv4 "show ip bgp summary").
Perché il processo BGP scanner allunga i tempi di convergenza ? Pensate per un momento che terminato un ciclo del processo, dopo qualche secondo un BGP Next-Hop divenga irraggiungibile. Il protocollo IGP se ne accorge abbastanza velocemente, ma a causa del BGP scanner, il processo BGP se ne accorge dopo poco meno di 60 sec (statisticamente, mettendosi al centro del periodo di scanning di default di 60 sec, dopo circa 30 sec). Questo comporta che per un certo tempo (al limite quasi 60 sec, utilizzando il valore di default), il traffico incorre, con alta probabilità, in forwarding loop e/o black-hole.
La differenza di velocità di convergenza tra IGP e BGP diventa qui molto evidente. Mentre il protocollo IGP rileva la perdita di un prefisso molto velocemente (tipicamente in meno di un secondo, e con tuning opportuni dei timer principali e l'introduzione della funzionalità LFA (Loop Free Alternate) anche con tempi dell'ordine delle poche decine di msec; nel seguito scriverò dei Post su questo), il BGP (Cisco !) ha tempi di convergenza di decine di secondi (al limite quasi 60).
L'ideale sarebbe avere una comunicazione immediata (o quasi immediata) da parte del protocollo IGP al BGP, che il BGP Next-Hop è diventato irraggiungibile. In particolare, sarebbe una buona cosa passare da una gestione della validazione del BGP Next-Hop di tipo time-driven (basata sul processo BGP scanner), ad una event-driven, basata su una comunicazione da IGP a BGP, sulla raggiungibilità del BGP Next-Hop.
LA FUNZIONE BGP NEXT-HOP TRACKING
Nella sua evoluzione, l'implementazione Cisco del BGP è passata, con l'introduzione della funzione "BGP Next-Hop Tracking" (da qui in poi abbreviata in BGP NHT), da una gestione time-driven a una gestione event-driven.
D'altro canto, questa funzione è stata sempre implementata nel JUNOS, che ha quindi utilizzato sempre un approccio di tipo event-driven (almeno a mia memoria, non ho informazioni sulla versione 1.1 del JUNOS !).
Vediamo allora un po' più da vicino come la funzione BGP NHT è implementata nei router Cisco. L'idea è quella di permettere al processo BGP di registrare i possibili BGP Next-Hop (con un processo chiamato "RIB watcher") e quindi di chiedere una sorta di avviso ogniqualvolta vi sia una variazione sulla raggiungibilità del BGP Next-Hop (in realtà, non solo la raggiungibilità, ma un qualsiasi cambio riguardante la raggiungibilità del BGP Next-Hop, come ad esempio il costo IGP per raggiungerlo, che ricordo, ha un impatto sul processo di selezione BGP). Si noti che il numero di BGP Next-Hop è di gran lunga inferiore al numero di prefissi appresi via BGP , per cui la funzione BGP NHT non è molto pesante per la CPU, né per il consumo di memoria (si pensi ad esempio a un router che riceve la Full Internet Routing Table da due ISP; i prefissi sono dell'ordine delle centinaia di migliaia (ad oggi più di 530k !), ma i BGP Next-Hop sono solo due).
Vediamo ora alcuni aspetti di configurazione nei router Cisco. Innanzitutto, in tutte le nuove versioni IOS (IOS, IOS XE, IOS XR, ecc.) la funzione BGP NHT è implementata di default (nell'IOS a partire dalle 12.0(29)S e 12.3(14)T). Può essere solo disabilitata (ad esempio, nel caso di flap del BGP Next-Hop, non risolto da meccanismi di damping, in altri casi solo se si viene colti da una sindrome tafazziana !) con il comando seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# no bgp nexthop trigger enable
Vi sono due altri aspetti di configurazione su cui vale la pena soffermarsi. Il primo riguarda il ritardo con cui il processo BGP utilizza le informazioni sui BGP Next-Hop ricevute dal protocollo IGP. Di default il BGP utilizza queste informazioni dopo un ritardo di 5 sec. Questo perché si da modo al BGP di collezionare più eventi comunicati dal protocollo IGP, e quindi di ottimizzarne l'elaborazione. Tipicamemente questo ritardo dovrebbe essere configurato a un valore leggermente superiore alla velocità di convergenza del protocollo IGP, ma è possibile anche configurarlo nullo, per fare in modo che ogni evento comunicato dal protocollo IGP venga elaborato immediatamente (attenzione però che questo potrebbe causare possibili oscillazioni delle route BGP, a causa di oscillazioni (cambi di stato) del BGP Next-Hop). Per variare questo ritardo, si utilizza il comando seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# bgp nexthop trigger delay <valore-in-sec>
Nei router 3825 del nostro laboratorio (IOS 15.1(3)T), l'intervallo dei valori ammessi è [0, 100].
L'altro aspetto di configurazione interessante, riguarda un problema che abbiamo già incontrato nel Post precedente quando abbiamo parlato del comando "neighbor ... fall-over": l'aggregazione di prefissi o la presenza nella RIB di una default-route, rende la funzione BGP NHT priva di efficacia. Infatti, se ad esempio nella propria RIB un router ha una default-route, o un prefisso aggregato che contiene un BGP Next-Hop, un eventuale cambio di stato del BGP Next-Hop non viene riportato al processo BGP, poiché nulla cambia nella RIB circa la raggiungibilità.
La "via di fuga" è utilizzare la funzionalità NHT estesa "BGP Selective Address Tracking" (introdotta a partire dall'IOS 12.4(4)T), che consente di selezionare a quali prefissi IP debbano appartenere i BGP Next-Hop da monitorare. Il comando che consente di attivare questa funzionalità è il seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# bgp nexthop route-map <nome-route-map>
dove la route-map consente di definire l'insieme dei BGP Next-Hop da monitorare. Se un BGP Next-Hop non appartiene a un prefisso permesso dalla route-map, questo viene considerato irraggiungibile. Di conseguenza, tutti i prefissi appresi via BGP che hanno questo BGP Next-Hop, non partecipano al processo di selezione BGP. Si noti che le uniche due condizioni "match" permesse nella route-map sono "match ip address ..." e "match source-protocol ...".
Vediamo ora con un esempio il funzionamento del "BGP Selective Address Tracking". Consideriamo lo scenario della figura seguente:
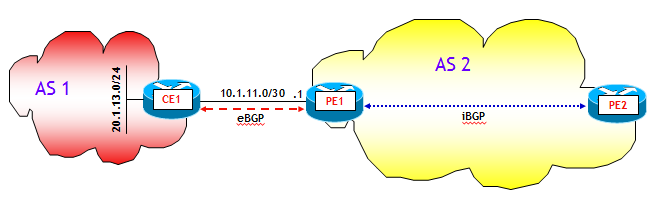
La sessione eBGP tra i router CE1 e PE1 è di tipo standard e utilizza come indirizzi IP gli indirizzi delle interfacce agli estremi del collegamento punto-punto. Inoltre, sul router PE1 non è stata configurata la funzione "next-hop-self", ne la subnet 10.1.11.0/30 è stata redistribuita nel protocollo IGP dell'AS 2. Ne consegue che su PE2, l'annuncio del prefisso 20.1.13.0/24 non è valido poiché per PE2 il BGP Next-Hop 10.1.11.2 non è raggiungibile:
PE2# show bgp ipv4 unicast 20.1.13.0 255.255.255.0
BGP routing table entry for 20.1.13.0/24, version 7
Paths: (1 available, no best path)
Flag: 0x820
Not advertised to any peer
1
10.1.11.2 (inaccessible) from 192.168.0.11 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal
Ora, supponiamo di configurare su PE2 una route statica fittizia con Next-Hop = null0, verso un prefisso IP che sia supernet del prefisso 10.1.11.0/30:
PE2(config)# ip route 10.1.0.0 255.255.0.0 null0
Incredibile ma vero, l'annuncio del prefisso 20.1.13.0/24 diventa valido, anche se per PE2 il BGP Next-Hop 10.1.11.2 rimane ovviamente irraggiungibile:
PE2# show bgp ipv4 unicast 20.1.13.0 255.255.255.0
BGP routing table entry for 20.1.13.0/24, version 8
Paths: (1 available, best #1, table Default-IP-Routing-Table)
Flag: 0x820
Not advertised to any peer
1
10.1.11.2 from 192.168.0.11 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal, best
Devo confessare che questo comportamento dell'IOS Cisco (e anche del JUNOS, come ho verificato con delle prove di laboratorio) ancora oggi mi lascia perplesso poiché si viola uno dei principi sacri del BGP: un annuncio può partecipare al processo di selezione BGP se e solo se il Next-Hop è raggiungibile (questo almeno recita RFC 4271). Non voglio entrare in una disputa accademica su questo comprtamento (ne ho avuta già una con il mio amico Ivan Pepelnjak, che asserisce che l'implementazione Cisco (e Juniper) è corretta, ma io non ne sono convinto). Vediamo però come con l'ausilio della funzione "BGP Selective Address Tracking" sia possibile rimettere le cose al loro posto. Spesso un BGP Next-Hop proviene da un prefisso /32 (tipico esempio quando si utilizzano per le sessioni BGP le interfacce di loopback) o da prefissi /30 o /31 (tipico esempio quando si utilizzano per le sessioni BGP gli indirizzi IP delle interfacce fisiche di collegamenti punto-punto). Con la funzione "BGP Selective Address Tracking" è possibile restringere l'insieme dei BGP Next-Hop validi, ad esempio consentendo validi solo i BGP Next-Hop che appartengono a prefissi nella RIB, che hanno lunghezza della maschera 30, 31 o 32. Questa è la configurazione da eseguire:
ip prefix-list GE-30 seq 5 permit 0.0.0.0/0 ge 30
!
route-map TEST permit 10
match ip address prefix-list GE-30
!
router bgp 2
bgp nexthop route-map TEST
L'annuncio BGP del prefisso 20.1.13.0/24, con questa configurazione non partecipa più al processo di selezione BGP, poiché l'unico prefisso nella RIB che lo contiene è il prefisso 10.1.0.0/16 (inserito con la route statica fittizia), che però non ha maschera superiore o al più uguale a 30, per cui non viene considerato per definire la raggiungibilità del BGP Next-Hop:
PE2# show bgp ipv4 unicast | i 20.1.13.0
* i20.1.13.0/24 10.1.11.2 0 100 0 1 i
LAB TEST
Della serie "se non vedo non credo", per verificare il funzionamento del BGP NHT ho effettuato una prova di laboratorio che mostra la differenza nei tempi di convergenza tra il BGP time-driven, ossia con la funzione NHT disabilitata, e il BGP event-driven. Lo scenario della prova è riportato nella figura seguente:
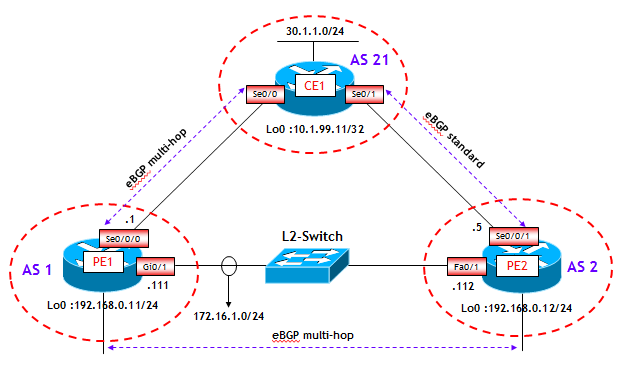
Le configurazioni base del BGP sui tre router sono le seguenti:
hostname PE1
!
router bgp 1
neighbor 10.1.99.11 remote-as 21
neighbor 10.1.99.11 ebgp-multihop 255
neighbor 10.1.99.11 update-source Loopback0
neighbor 192.168.0.12 remote-as 2
neighbor 192.168.0.12 ebgp-multihop 255
neighbor 192.168.0.12 update-source Loopback0
!
hostname PE2
!
router bgp 2
neighbor 10.1.12.6 remote-as 21
neighbor 192.168.0.11 remote-as 1
neighbor 192.168.0.11 ebgp-multihop 255
neighbor 192.168.0.11 update-source Loopback0
!
hostname CE1
!
router bgp 21
network 30.1.1.0 mask 255.255.255.0
neighbor 10.1.12.5 remote-as 2
neighbor 192.168.0.11 remote-as 1
neighbor 192.168.0.11 ebgp-multihop 255
neighbor 192.168.0.11 update-source Loopback0
Supponiamo inizialmente di disabilitare sul router PE1 la funzione BGP NHT:
router bgp 1
address-family ipv4
no bgp nexthop trigger enable
e di attivare il "debug ip routing":
PE1# debug ip routing
Come passo successivo, mettiamo in "shutdown" l'interfaccia Loopback 0 di CE1, che è quella utilizzata per la sessione eBGP multi-hop con PE1:
CE1(config)# interface loopback 0
CE1(config-if)# shutdown
Vediamo cosa accade su PE1. Innanzitutto, con i tempi di convergenza del protocollo IGP (che nel mio caso è l'OSPF base, con i timer non ottimizzati), PE1 cancella dalla propria RIB il prefisso 10.1.99.11/32 (indirizzo dell'interfaccia Loopback 0 di CE1):
*Oct 31 13:59:37.407: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 13:59:37.407: RT: delete subnet route to 10.1.99.11/32
Ho verificato quindi immediatamente la Tabella BGP di PE1, dalla quale si vede che PE1 ancora crede che il suo BGP Next-Hop sia 10.1.99.11:
PE1# show bgp ipv4 unicast
(output omesso)
Network Next Hop Metric LocPrf Weight Path
* 30.1.1.0/24 192.168.0.12 0 2 21 i
*> 10.1.99.11 0 0 21 i
Ma ovviamente l'indirizzo 10.1.99.11 non è più raggiungibile:
PE1# ping 10.1.99.21
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.99.21, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Cosa sta accadendo ? Semplice, il processo BGP scanner su PE1 (che ha un periodo di default di 60 sec, che ho lasciato inalterato) ancora non ha verificato la raggiungibilità del BGP Next-Hop, che rimane quindi quello iniziale. Dopo un po', il processo riprende la verifica di raggiungibilità del BGP Next-Hop, e poiché si accorge che questo non è più raggiungibile dalla RIB, riesegue il processo di selezione BGP e converge sul best-path alternativo 192.168.0.12.
*Oct 31 14:00:32.487: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:00:32.487: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:00:32.487: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
PE1# show bgp ipv4 unicast
(output omesso)
Network Next Hop Metric LocPrf Weight Path
*> 30.1.1.0/24 192.168.0.12 0 2 21 i
* 10.1.99.11 0 0 21 i
Quanto ha impiegato il BGP a convergere sul nuovo best-path ? Presto detto, dagli output dei debug si evince un tempo di poco più di 35 sec ! E mi è andata bene, il tempo poteva anche essere maggiore, visto che il periodo di scanning è 60 sec.
Abilitiamo ora il BGP NHT. Per corretteza dovrei dire "riabilitiamo" il BGP NHT, perché come già detto il BGP NHT è abilitato di default nelle versioni IOS recenti (per la cronaca, il router PE1 è un Cisco 3825 con IOS 15.1(3)T).
Abilitiamo ora il BGP NHT. Per corretteza dovrei dire "riabilitiamo" il BGP NHT, perché come già detto il BGP NHT è abilitato di default nelle versioni IOS recenti (per la cronaca, il router PE1 è un Cisco 3825 con IOS 15.1(3)T).
router bgp 1
address-family ipv4
bgp nexthop trigger enable
Ripetendo la procedura precedente, ecco cosa accade su PE1:
*Oct 31 14:10:32.843: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 14:10:32.843: RT: delete subnet route to 10.1.99.11/32
*Oct 31 14:10:37.843: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:10:37.843: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:10:37.843: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
Come si può notare, adesso il BGP converge sul best-path alternativo 192.168.0.12, dopo soli 5 sec, che è il valore di default del BGP NHT "trigger delay". Ho rifatto la prova ponendo a zero questo valore:
router bgp 1
address-family ipv4
bgp nexthop trigger delay 0
Ecco il risultato:
*Oct 31 14:13:48.591: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 14:13:48.591: RT: delete subnet route to 10.1.99.11/32
*Oct 31 14:13:48.595: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:13:48.595: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:13:48.595: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
Il tempo di convergenza è diventato 4 ms !!! Attenzione però, questo è solo il tempo impiegato dal router PE1 per convergere al nuovo best-path. Il tempo di convergenza complessivo dipende dal tempo impiegato dal protocollo IGP a comunicare a PE1 il fuori servizio dell'interfaccia Loopback 0 di CE1. E questo apre a una interessante considerazione, il tempo di convergenza del BGP dipende fortemente dal tempo di convergenza del protocollo IGP. Ma su questo avremo modo di ritornare nei prossimi Post.
BGP FALLOVER E BGP NHT : DIFFERENZE
A volte sorge il sospetto (o il dubbio) che la funzionalità "BGP Fallover", introdotta nel Post precedente sulla convergenza del BGP, abbia lo stesso scopo della funzione BGP NHT, e che quindi una delle due sia inutile. Per evitare qualsiasi dubbio e confusione, voglio, per chiudere, mettere in evidenza le differenze tra queste due funzioni. Come visto nel precedente Post, la funzionalità "BGP Fallover" serve per chiudere una sessione i/eBGP, a fronte della perdita della raggiungibilità dell'indirizzo del BGP peer, ossia, quando non vi è più nella RIB un percorso per raggiungere l'indirizzo IP del BGP peer.
Come invece ampiamente visto in questo Post, il BGP NHT è un criterio event-driven che serve a verificare la raggiungibilità del BGP Next-Hop (che non necessariamente coincide con l'indirizzo del BGP peer; un esempio tipico si ha in presenza di Route Reflector, dove BGP Next-Hop e indirizzo del BGP peer non coincidono praticamente mai). Qualora il BGP Next-Hop non fosse più raggiungibile, la sessione BGP non verrebbe necessariamente chiusa (a meno che il BGP Next-Hop non coincida con l'indirizzo del BGP peer, come ad esempio quando si utilizza il comando "neighbor ... next-hop-self", o quando un router inserisce localmente nella Tabella BGP un prefisso da propagare), ma il processo BGP si limita a ritirare il prefisso, al ricalcolo del best-path e al riannuncio del nuovo best-path. Nel caso in cui non vi sia un nuovo best-path disponibile, il prefisso viene solo ritirato.
CONCLUSIONI
Con questo Post ho aggiunto un altro piccolo tassello per sfatare il mito della convergenza lenta del BGP. Vi avverto però, la strada da fare è ancora lunga, mancano all'appello concetti e funzionalità importanti come la PIC (Prefix Independent Convergence), Add-Path, BGP best-external, Diverse-Path e altro ancora. Prometto che alla fine raccoglierò tutti questi Post in un documento organico sulla convergenza del BGP, che sarà reso disponibile in download gratuito su questo Blog.
Volete saperne una più del diavolo sul BGP ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247 (nel qual caso il libro è parte della documentazione del corso).
Volete saperne una più del diavolo sul BGP ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247 (nel qual caso il libro è parte della documentazione del corso).
