

Il BGP è oggi sicuramente il protocollo più importante delle reti IP. Specificato per la prima volta nel lontano 1989 (RFC 1105 , Giugno 1989), è ancora oggi un protocollo in evoluzione, oggetto di continua attenzione, e al quale vengono assegnati compiti sempre maggiori.
Benché nato come protocollo di routing inter-dominio, il BGP ha esteso negli anni il suo ambito di applicazione e oggi, oltre al suo utilizzo storico, viene utilizzato:
- Nelle moderne reti dei grandi ISP (Internet Service Provider), dove gioca un ruolo chiave nell’architettura di routing complessiva poiché, grazie alla sua provata scalabilità, si è dimostrato uno strumento molto efficiente per distribuire all’interno di un AS i prefissi IP esterni all’AS.
- Nel piano di controllo di vari servizi basati sul modello BGP/MPLS (L3VPN, L2VPN, Trasporto IPv6, Multicast VPN, ecc.).
- Come protocollo di accesso di reti private (reti Enterprise) alle reti degli ISP.
Vi sono molti miti che circondano il protocollo BGP, che pian piano cercheremo di sfatare. Uno di questi miti è legato alla velocità di convergenza, ritenuta da tutti molto lenta. In realtà questo era vero nelle prime implementazioni del BGP, ma oggi, grazie a nuove funzionalità introdotte dai principali costruttori, e alcune oggetto di standard IETF, le cose sono cambiate radicalmente e la velocità di convergenza del BGP sta diventando comparabile con quella dei più importanti protocolli IGP come OSPF e IS-IS.
Agli albori del BGP, i progettisti, dato il suo ruolo di protocollo di routing inter-dominio, focalizzarono più l'attenzione sulle sue capacità di gestire quantità elevate di annunci, sacrificando a questo gli aspetti di convergenza, non considerati importanti nel suo ruolo originario.
Le cose sono cambiate radicalmente quando il BGP è diventato l'elemento intelligente dei servizi basati sul modello BGP/MPLS. Poiché questi servizi sono dedicati alla Clientela Business (di qualsiasi grandezza), improvvisamente i problemi di velocità di convergenza sono diventati di primaria importanza.
Vediamo dapprima quali sono le ragioni per la lenta convergenza del BGP, analizzando il tipico scenario nel quale un router perde la sessione con un BGP neighbor:
Sebbene la tabella di routing IP indichi che il BGP neighbor non è più raggiungibile, il BGP non inizia il processo di convergenza fino a quando la sessione BGP non cade. Questo avviene o per scadenza dell'Holdtime (il cui valore di default è molto alto, 180 sec nei router Cisco e 90 sec nei router Juniper), o per caduta della connessione TCP a causa dei timeoute dei TCP ACK.
Il BGP limita l'invio di batch di messaggi UPDATE, utilizzando il timer MRAI (MinRouteAdvertisementIntervalTimer), che è il tempo minimo tra due messaggi UPDATE inviati a un BGP neighbor, che annunciano o ritirano un particolare prefisso. Benché si applichi per prefisso, di solito i costruttori utilizzano un valore unico per BGP neighbor. Nei router Cisco ad esempio il MRAI è di default 5 sec per gli annunci iBGP e ben 30 sec per gli annunci eBGP. Questi valori sono configurabili attraverso il comando "neighbor ... advertisement-interval xxx".
Il BGP si affida spesso a un protocollo IGP per la determinazione del best-path. Nel caso di perdita del percorso verso il BGP neighbor, ad esempio, anche se il protocollo IGP rileva velocemente la perdita del BGP neighbor, non è detto che il BGP reagisca velocemente a questo cambiamento. Ad esempio, nell'implementazione "storica" del BGP Cisco, la presenza in tabella di routing del BGP neighbor veniva verificata ogni 60 sec (BGP Scan Time).
Vi sono molte altre variabili, ma meno importanti, che regolano la velocità di reazione del BGP. In questo Post focalizzeremo l'attenzione su un problema di primaria importanza: come sia possibile velocizzare la determinazione da parte del BGP della caduta di una sessione. In Post successivi vedremo invece come il BGP può velocizzare la determinazione del nuovo Next-Hop da utilizzare per il forwarding del traffico. E quest'ultimo è il problema più complesso e interessante, per il quale vi sono nuove funzionalità introdotte di recente, adirittura alcune ancora non completamente standardizzate da RFC.
LA FUNZIONALITA' "FAST EXTERNAL FALL-OVER"
Il primo "turbo" alla velocità di convergenza del BGP si è avuto molti anni fa con la funzionalità "fast external fall-over", introdotta ad esempio da Cisco nella relase 10.0 e da Juniper credo da sempre, ma non ho notizie precise in merito. Quando si utilizzano solo le funzioni base del BGP, per rilevare la perdita di una sessione BGP si fa affidamento ai timer associati ai messaggi BGP KEEPALIVE, periodo e Holdtime, che però sono molto alti (i valori di default sono 60/180 sec nell'implementazione Cisco e 30/90 sec nell'implementazione Juniper). E' possibile variare questi due timer fino a portarli a valori molti bassi, ma il rischio che la sessione BGP vada in "flapping" diventa molto concreto, e poi incrementerebbe di molto l'utilizzo della CPU a causa della maggiore frequenza dei messaggi BGP KEEPALIVE.
La funzionalità "fast external fall-over", che si applica alle sole sessioni eBGP tra router direttamente connessi, con gli estremi della connessione TCP coincidenti con gli indirizzi IP delle interfacce agli estremi del collegamento, parte da una osservazione elementare: la sessione eBGP viene disconnessa (con tutte le conseguenze del caso, eliminazione di router e ricalcolo dei best-path) non appena il router si accorge che dalla Tabella di Routing scompare la subnet IP (direttamente connessa) utilizzata per numerare le interfacce agli estremi del collegamento.
Per fare un esempio, consideriamo i due router Cisco della figura seguente, collegati direttamente con un link punto-punto, le cui interfacce agli estremi siano parte della subnet IP 10.1.11.0/30.

E' possibile quantificare l'azione della funzionalità "fast external fall-over", semplicemente analizzando i messaggi di consolle, ad esempio del router PE1:
Con la funzionalità "fast external fall-over" abilitata:
*Sep 29 09:26:33.255: %BGP-5-ADJCHANGE: neighbor 10.1.11.2 Down Interface flap
*Sep 29 09:26:33.255: %BGP_SESSION-5-ADJCHANGE: neighbor 10.1.11.2 IPv4 Unicast topology base removed from session Interface flap
*Sep 29 09:26:35.255: %LINK-5-CHANGED: Interface Serial0/0/0, changed state to administratively down
*Sep 29 09:26:36.255: %LINEPROTO-5-UPDOWN: Line protocol on Interface Serial0/0/0, changed state to down
Con la funzionalità "fast external fall-over" disabilitata:
*Sep 29 09:28:31.127: %LINK-5-CHANGED: Interface Serial0/0/0, changed state to administratively down
*Sep 29 09:28:32.127: %LINEPROTO-5-UPDOWN: Line protocol on Interface Serial0/0/0, changed state to down
*Sep 29 09:30:32.371: %BGP-5-ADJCHANGE: neighbor 10.1.11.2 Down BGP Notification sent
*Sep 29 09:30:32.371: %BGP-3-NOTIFICATION: sent to neighbor 10.1.11.2 4/0 (hold time expired) 0 bytes
*Sep 29 09:30:32.371: %BGP_SESSION-5-ADJCHANGE: neighbor 10.1.11.2 IPv4 Unicast topology base removed from session BGP Notification sent
Come si può notare, senza la funzionalità "fast external fall-over" la sessione BGP cade dopo poco più di 2 minuti, ossia alla scadenza dell'Holdtime. Con la funzionalità "fast external fall-over" abilitata, la caduta della sessione è rilevata invece in tempo quasi reale (nell'esempio, l'IOS Cisco notifica immediatamente al processo BGP il "down" dell'interfaccia e la sessione viene immediatamente abbattuta, addirittura prima del "down" effettivo dell'interfaccia).
La funzionalità "fast external fall-over" è abilitata di default e nei router Cisco è possibile disabilitarla con il comando a livello di processo BGP "no bgp fast-external-fallover" (nell'IOS XR il comando equivalente è "bgp fast-external-fallover disable").
E' importante notare che la funzionalità non si applica al caso di sessioni eBGP-multihop. Per questo è necessario un altro meccanismo, che si applica anche alle sessioni iBGP e che vedremo a breve.
La funzionalità "fast external fall-over" così come descritta ha però un problema, funziona solo con collegamenti back-to-back, ossia collegamenti realizzati senza apparati intermedi. Per capire questo problema e come risolverlo, si consideri la situazione della figura seguente, dove il collegamento punto punto-punto tra i router PE1 e PE2 è realizzato attraverso una banale VLAN su un switch Ethernet.
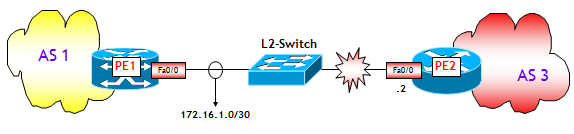
Cosa accade quando, ad esempio, cade il collegamento tra switch Ethernet e il router PE2 ? Bene, in questo caso la funzionalità "fast external fall-over" entra in funzione solo su PE2 ma non su PE1, che vede l'interfaccia di collegamento al switch Ethernet nello stato up/up. In soldoni, mentre PE2 chiude immediatamente la sessione, PE1 chiude la sessione dopo la scadenza dell’Holdtime (ad esempio, nei router Cisco, nell’ipotesi peggiore dopo quasi tre minuti !). Questa è la sequenza di ciò che avviene, dopo un fuori servizio del collegamento tra PE2 e L2-Switch (simulato da uno shutdown dell’interfaccia Fa0/0 di PE2):
Sul router PE2
*Sep 29 12:29:59.803: %BGP-5-ADJCHANGE: neighbor 172.16.1.1 Down Interface flap
*Sep 29 12:30:01.695: %LINK-5-CHANGED: Interface FastEthernet0/0, changed state to administratively down
*Sep 29 12:30:01.699: %ENTITY_ALARM-6-INFO: ASSERT INFO Fa0/0 Physical Port Administrative State Down
*Sep 29 12:30:02.695: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/0, changed state to down
Sul router PE1
*Sep 29 12:32:39.475: %BGP-5-ADJCHANGE: neighbor 172.16.1.2 Down BGP Notification sent
*Sep 29 12:32:39.479: %BGP-3-NOTIFICATION: sent to neighbor 172.16.1.2 4/0 (hold time expired) 0 bytes
Come si può notare, PE1 chiude la sessione dopo poco meno di tre minuti dalla chiusura da parte di PE2.
Come si può risolvere il problema ? Qui ci viene in aiuto un protocollo standard abbastanza recente, ma a molti sconosciuto (me ne sono reso conto personalmente durante le mie lezioni). Il protocollo in questione è il BFD (Bidirectional Forwarding Detection), specificato nelle RFC 5880 "Bidirectional Forwarding Detection (BFD)" e RFC 5881 "Bidirectional Forwarding Detection (BFD) for IPv4 and IPv6 (Single Hop)", Giugno 2010 (esiste anche la versione multi-hop, vedi RFC 5883 e una versione per MPLS, vedi RFC 5884 "Bidirectional Forwarding Detection (BFD) for MPLS Label Switched Paths (LSPs)"). Non voglio entrare nei dettagli di funzionamento del BFD poiché ne farò oggetto di uno dei prossimi Post, ma darvi l'idea di fondo, che per la verità è molto semplice. Il BFD consente una rapida rilevazione di fuori servizio di collegamenti e/o percorsi in modo indipendente dal protocollo routing utilizzato e dal Livello 2. Il protocollo è basato su un classico meccanismo di HELLO molto «leggeri» e veloci. L’aspetto chiave del BFD è che i BFD HELLO vengono direttamente elaborati dal piano dati, senza quindi impegnare la CPU.
Le varie versioni dell’IOS Cisco supportano il BFD per il BGP solo per le sessioni eBGP di tipo single-hop. Solo in alcune piattaforme è stata introdotta recentemente la versione multi-hop. I router Juniper supportano entrambe le versioni.
La figura seguente riporta un esempio di configurazione del BFD nelle varie versioni dell’IOS Cisco.
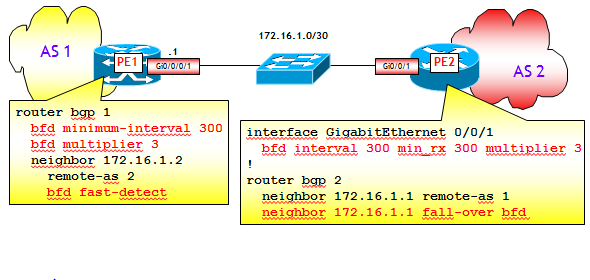
Nell’IOS e IOS XE la configurazione prevede dapprima l’abilitazione del BFD a livello interfaccia. Il comando, un esempio del quale è riportato nella figura, richiede tre parametri:
- interval : è il periodo dei messaggi BFD HELLO inviati (espresso in ms).
- min_rx : è l’intervallo minimo tra due messaggi BFD HELLO provenienti dai BFD peer.
- multiplier : è il numero di messaggi BFD HELLO che possono essere persi prima di dichiarare il collegamento down. Il valore consigliato nelle applicazioni pratiche è 3.
Successivamente, è necessario abilitare il BFD a supporto del BGP, tramite il comando "neighbor x.y.z.w fall-over bfd". Poiché l’IOS Cisco supporta la modalità asincrona del BFD, è necessario abilitare il BFD su entrambi i lati del collegamento.
Nell’IOS XR la configurazione avviene solamente all’interno del processo BGP, dove vanno definiti il periodo dei messaggi BFD HELLO ("minimum-interval periodo-in-ms") e valore di "multiplier" (con lo stesso significato visto sopra per l’IOS e IOS XE). All’interno del singolo BGP neighbor è quindi necessario abilitare il BFD con il comando «bfd fast-detect».
Un esempio di configurazione nel JUNOS è riportato nella figura seguente.

Vediamo ora l’effetto della configurazione nel caso di un fuori servizio del collegamento tra PE2 e il switch L2. Come già detto, senza il BFD, PE2 chiude immediatamente la sessione mentre PE1 chiude la sessione alla scadenza dell’Holdtime. Con il BFD abilitato invece, come si nota dai risultati dei comandi "show log bgp.log" seguenti, sia PE1 che PE2 chiudono quasi contemporaneamente la sessione BGP (PE1 la chiude dopo poco più di 1,5 sec, essendo il tempo di rilevamento del fuori servizio 5*300 = 1.500 ms):
tt@PE2> show log bgp.log
Nov 25 08:22:41.982350 bgp_ifachange: interface 172.20.1.2(fe-0/0/0.0) went down, state <Broadcast Multicast>, chng <UpDown>, instance master, checking who this bothers
Nov 25 08:22:41.982372 bgp_affected2: peer 172.20.1.1 (External AS 1) idled, shared interface went down
Nov 25 08:22:41.982392 bgp_ifachange_group:6289: NOTIFICATION sent to 172.20.1.1
(External AS 1): code 6 (Cease) subcode 6 (Other Configuration Change), Reason:Interface change for the peer-group
. . .
tt@PE1> show log bgp.log
Nov 25 08:22:43.820435 bgp_peer_close: closing peer 172.20.1.2 (External AS 2), state is 7 (Established)
Nov 25 08:22:43.821347 bgp_event: peer 172.20.1.2 (External AS 2) old state Established event Restart new state Idle
LA FUNZIONALITA' "FAST PEERING DEACTIVATION"
La funzionalità "fast external fall-over" descritta sopra non è applicabile a sessioni iBGP né a sessioni eBGP multi-hop. Che alternative si hanno a disposizione in questo caso, a parte il solito tuning del periodo dei BGP KEEPALIVE e dell'Holdtime ? A partire dalle versioni IOS 12.0S e 12.3T, Cisco mette a disposizione il supporto per la funzionalità "Fast Peering Deactivation", applicabile sia a sessioni iBGP che eBGP multi-hop. L'idea è abbastanza semplice: non appena l'indirizzo IP del BGP neighbor non è più raggiungibile dalla Tabella di Routing, la sessione viene immediatamente disattivata.
La funzionalità "Fast Peering Deactivation", si attiva nei router Cisco tramite il comando IOS/IOS XE "neighbor x.y.z.w fall-over". Non mi risulta sia presente nell'IOS XR un comando analogo (almeno fino alla release 4.2.1, se qualcuno ha notizie diverse è pregato di segnalarlo con un commento).
Si consideri come esempio la rete della seguente figura.
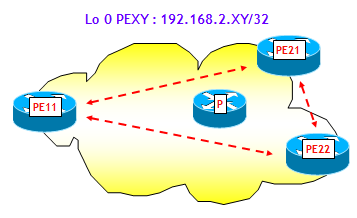
La configurazione BGP sul router PE1 sia la seguente:
router bgp 1
neighbor 192.168.2.21 remote-as 1
neighbor 192.168.2.21 update-source loopback 0
neighbor 192.168.2.21 fall-over
neighbor 192.168.2.22 remote-as 1
neighbor 192.168.2.22 update-source loopback 0
neighbor 192.168.2.22 fall-over
In alternativa è possibile utilizzare la seguente configurazione, più elegante e scalabile, che utilizza i BGP peer-template:
router bgp 1
template peer session iBGP
remote-as 1
update-source loopback 0
fall-over
!
neighbor 192.168.2.21 inherit peer-session iBGP
neighbor 192.168.2.22 inherit peer-session iBGP
Supponiamo che l'intero router PE2 vada fuori servizio. Attivando su PE1 il comando "debug ip routing" si ottiene quanto segue:
*Sep 29 16:36:38.527: RT: NET-RED 192.168.2.21/32
*Sep 29 16:36:38.531: RT: del 192.168.2.21/32 via 172.20.13.12, ospf metric [110/21]
*Sep 29 16:36:38.535: RT: delete subnet route to 192.168.2.21/32
*Sep 29 16:36:38.535: RT: NET-RED 192.168.2.21/32
... < output omesso > ...
*Sep 29 16:36:38.567: RT: Try lookup less specific 192.168.2.21/32, default 1
*Sep 29 16:36:38.571: RT: Failed found subnet on less specific
*Sep 29 16:36:38.571: RT: return NULL
*Sep 29 16:36:38.611: %BGP-5-ADJCHANGE: neighbor 192.168.2.21 Down Route to peer lost
Come si può notare, non appena il router PE1 non riesce più a trovare un percorso verso il BGP neighbor 192.168.2.21/32, la sessione iBGP tra PE1 e PE21 viene disattivata.
E' ovvio che la bontà di questo approccio dipende fortemente dalla velocità di convergenza del protocollo IGP (nell'esempio abbiamo utilizzato OSPF).
La funzionalità "Fast Peering Deactivation" ha però un problema: l'aggregazione di prefissi o la presenza in tabella di routing di una default-route rende la funzionalità inapplicabile. In altre parole, se ad esempio in Tabella di Routing il router PE1 ha una default-route, magari annunciata via OSPF da PE21, la connettività verso il BGP neighbor 192.168.2.21/32 non viene considerata persa e quindi il meccanismo non funziona (nel senso che la sessione BGP disattivata solo allo scadere dell'Holdtime).
Ci sono due "vie di fuga" possibili. La prima è quella di annunciare la default-route via BGP, piuttosto che via OSPF, poiché le route BGP non vengono considerate tra le possibili alternative per raggiungere il BGP neighbor. La seconda "via di fuga" è utilizzare la funzionalità estesa "Selective Address Tracking for BGP Fast Session Deactivation", introdotta nella versione IOS 12.4(4)T, che consiste nell'aggiungere al comando "neighbor x.y.z.w fall-over" una route-map che consenta di selezionare quali prefissi IP debbano essere monitorati per determinare la caduta della sessione iBGP. Ritornando al nostro esempio, le interfacce Loopback0 utilizzate come estremi delle sessioni iBGP sono tutte subnet /32 del prefisso IP 192.168.2.0/24. Nella configurazione è quindi possibile aggiungere una route-map che permetta tutte le subnet /32 del prefisso 192.168.2.0/24 e il problema è risolto. Le configurazioni aggiuntive sono le seguenti:
ip prefix-list LOOPB seq 5 permit 192.168.2.0/24 ge 32
!
route-map BGP-NEIGHBOR permit 10
match ip address prefix-list LOOPB
match source-protocol ospf 1
!
router bgp 1
template peer session iBGP
remote-as 1
update-source loopback 0
fall-over route-map BGP-NEIGHBOR
!
neighbor 192.168.2.21 inherit peer-session iBGP
neighbor 192.168.2.22 inherit peer-session iBGP
Una nota a latere: la configurazione appena esposta mostra un chiaro esempio di scalabilità della configurazione consentito dall'utilizzo dei BGP peer-templates, oggi consigliati in sostituzione dei vecchi BGP peer-group (una modalità di configurazione simile nell'IOS XR è costituita dai BGP Configuration Templates).
CONCLUSIONI
Il BGP, a più di 25 anni dalla sua nascita, è ancora un protocollo vivo e intrigante, oggetto sempre di nuovi studi e supporto fondamentale di nuovi servizi. Negli ultimi anni l'attenzione si è focalizzata soprattutto a migliorare la sua velocità di convergenza, in passato il suo vero tallone d'Achille. Sono state introdotte nuove funzionalità e nuove migliorie al codice. In questo Post abbiamo visto come sia possibile velocizzare la disconnessione di una sessione BGP senza ricorrere ai timer classici associati ai messaggi BGP KEEPALIVE. Questa a dire il vero è la parte facile del problema. Nei prossimi Post affronteremo invece la parte più complessa, ossia come determinare il nuovo Next-Hop a fronte di diversi tipi di guasto
Siete nuovi al BGP, oppure avete bisogno di ulteriori approfondimenti ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247.
